What is the big deal? The size of the drive is reported by the forensic tool and I just need to bookmark it or document it. Forensic tools are tested and vetted in courts, so I don't need to worry about them. Right? The answer is not that simple since 1998. In 1998 the International Electrotechnical Commission (IEC) decided to resolve the old standing conflict of orders of magnitudes like kilo or mega that are used to represent a Base-10 prefix and not a Base-2 prefix. Thus, a 1000m run can be referred to as a 1Km while a 1024 Byte memory block is referred to as 1KiB, 1 kibibyte.
The calculation does not change, only the unit of measure reflects the binary nature the order of magnitude.
There is not much focus on this change and many experts might not even know about it, but it is annoying if the tools we use do not confirm to this changed standard. As long as we can refer to the byte value, there is no problem since only the prefix that needs to be examined for the correct spelling.
I have seen the hard drive manufacturers following this new standard for years now while the software vendors lagging behind.
http://www.seagate.com/www-content/product-content/nas-fam/nas-hdd/en-us/docs/100724684.pdfi.e.
7814037168 * 512 = 4000787030016 / 1000000000 = 4TB.
So, what do we see in forensic tools, in operating systems, and in generic tools? Well, it depends.
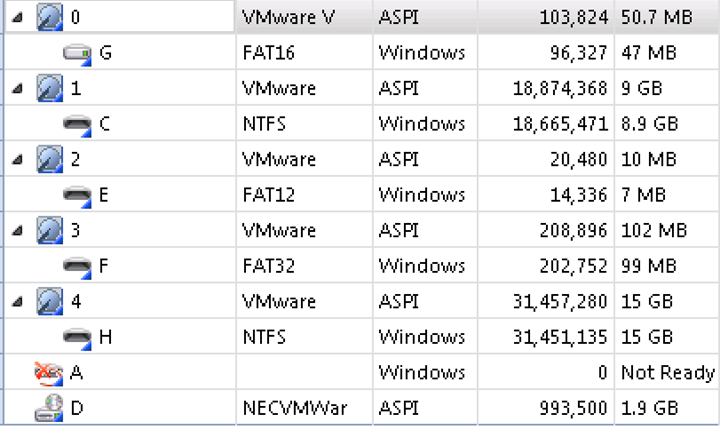
AccessData FTK Imager 3.1.3 calculates the drive sizes for an easy and quick reference. We can also easily find the drive sector sizes in this tool.
Physicaldrive0 Sector Count = 103,824 = 53157888 bytes
Physicaldrive1 Sector Count = 18,874,368 = 9663676416 bytes
Physicaldrive2 Sector Count = 20,480 = 10485760 bytes
Physicaldrive3 Sector Count = 208,896 = 106954752 bytes
Physicaldrive4 Sector Count = 31,457,280 = 16106127360 bytes
Reference calculations:Physicaldrive0 Size = 50.69MiB or 53.15MBPhysicaldrive1 Size = 9GiB or 9.66 GBPhysicaldrive2 Size = 10MiB or 10.48MBPhysicaldrive3 Size = 102MiB or 106.95MBPhysicaldrive4 Size = 15GiB or 16.1GBSample calculation based on PhysicalDrive4
| Total Sectors | 31,457,280 |
| Bytes | 16106127360 |
| International Electrotechnical Commission (IEC) | International System of Units System ( Metric ) |
| Kibibytes | KiB | 15728640 | kilobyte | kB | 16106127 |
| megibyte | MiB | 15360 | megabyte | MB | 16106.127 |
| gibibyte | GiB | 15 | gigabyte | GB | 16.106127 |
I'm not really sure where FTK Imager got some of the values for its physical size, drive 1 seems to be in GiB, drive 2 is a mystery number, drive 3 seems to be in MB, and drive in GB.
Encase_forensic_imager_7.06 also shows the cluster count and the drive sizes in an easy format. It also lists the sizes in a Base-2 format while using the Base-10 unit of measures, but it is more consistent than FTK Imager.
Windows Management Instrumentation Command-line (
WMIC) shows the physical devices, but the size and total sectors are not the physical size values.
Windows shows the physical sizes, but not even close to the actual size of the devices, but we know from the MBR master partition table calculations that partition size calculations are based on Base-2 calculations.
Example value calcualted from MBR of Disk 1, first partition entry.
00200300 = 0x32000 = 204,800 sectors in partition, thus the value of the number of bytes in the partition is 204800*512 = 104857600 bytes / ( 1024 * 1024 * 1024 ) = 100MiB
So, Microsoft is using the wrong measures of unit to display storage device size information. Disk 2 and Disk 3 size values are way off from either of the calculated values, but those that are the right values, those are calculated by the Base-2 conversion method, so the unit of measures should be MiB and GiB not MB and GB.
Linux on the other hand is using the Base-10 conversion for the correct unit of measures in MB and GB.
/dev/hda size was an anomaly and I was not able to find a suitable explanation why the value was off, but it might have had something to do with a virtual IDE hard drive. I have verified the existence of sector 104447 using dcfldd and xxd ( dcfldd if/dev/hda bs=512 skip=104447|xxd ). Even though all other tools showed only 103,824 sectors on the drive, I did locate 104448.
/dev/sda->18874368 sectors consistent with other Windows tools, but the capacity is correctly calculated in MB to 9663MB or 9.66GB.
/dev/sdb->
20480 sectors consistent with other Windows tools, but the capacity is correctly calculated in MB to 10MB.
/dev/sdc->
208896 sectors consistent with other Windows tools, but the capacity is correctly calculated in MB to 106MB.
/dev/sdd->
31457280 sectors consistent with other Windows tools, but the capacity is correctly calculated in GB to 16.1GB.
So, my conclusion is that Windows based software vendors did not make the adjustment in the last 16 years to label their storage device sizes properly. The most surprising are the forensic tool vendors not seeing the need to label properly or show the proper capacity of the drives. As long as the size is referred to in bytes, the values are correct and it might be needed to start referring to evidence size in bytes to avoid confusion.